What are Distributed Systems


Pre-requisites:
What is a robust system?-A system that has capability to cope with errors
What is Scalable System?- A system that can handle increase or decrease of load with no drop in performance
What is vertical scaling?-Scaling a system by adding more power to an existing machine. In other words, It is upgrading existing software or hardware
What is horizontal scaling?-Scaling a system by adding more instances of a machine. There is no upper limit to the number of instances that can be added.
So What is a Distributed system?
Any system which includes multiple components residing on multiple machines coordinating through some sort of mechanism like sending messages to achieve a common goal is a distributed system.
Example: Uber
Multiple components - Driver, Rider, Uber servers etc.
Multiple Machines- Driver app, Rider app, Machines on which Uber servers reside
Common Goal: To connect riders and drives
There are 3 principles that usually guide a robust and scalable distributed system:
Single responsibility Principle - Each component present in System Design should have a single job to perform
No single point of failure principle - The system should never have any component whose failure will result in the failure of the entire system
No bottleneck principle - Since we design for scalability our system should not have performance bottlenecks. Ideally we should horizontally scale our system to handle the large amounts of processing
Application of these principles:
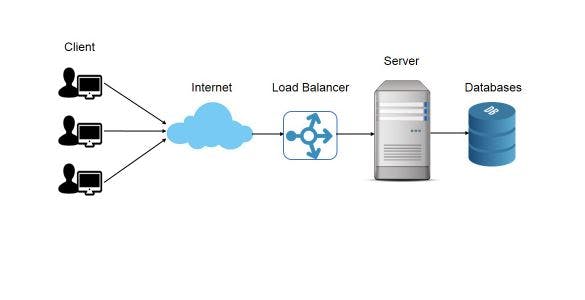
Consider the above example where we have a simple system. In the above system, clients make request. The requests are distributed to servers through a load balancer. The server may do two things- it may process the data and store the data in the database and/or it may server web pages in response to requests from the client.
Application of principle: Single responsibility Principle
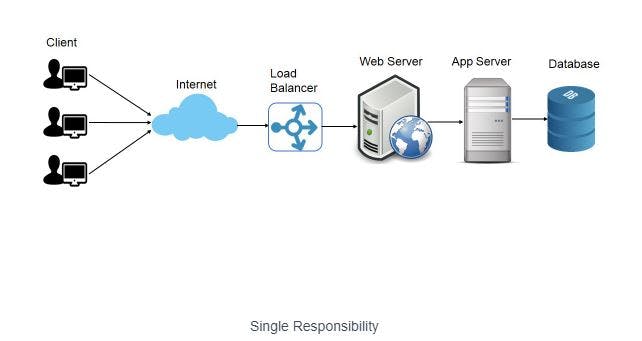
Since there are two different activities a server can perform. In a distributed system, we may separate the servers into Web servers and Application Server. Web servers will be responsible to server web pages in response to requests and App servers will process data and hit database to store the data.
Application of principle: No single point of failure principle
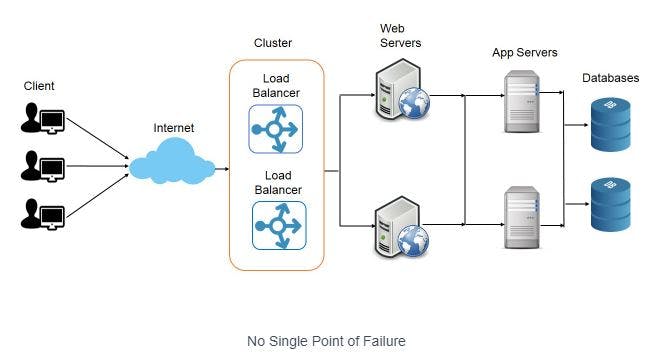
According to the second principle, all single point of failures need to be eliminated. Therefore , as show above, we have replicas of load balancer, Web servers and Application servers so failure of one component will not bring down the entire system. This increases the Availability of our system.
Application of principle: No bottleneck
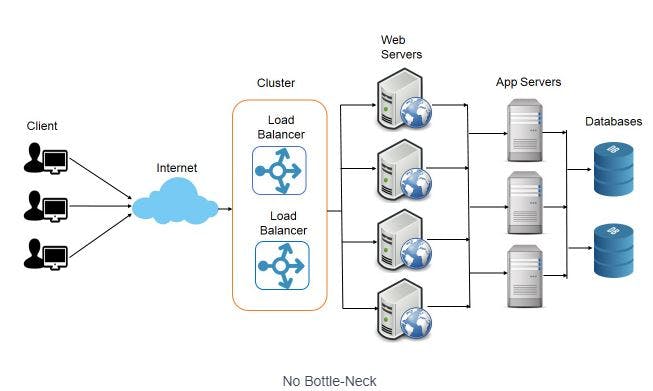
Consider a scenario where each our server can handle only 100 requests per min. If we have only 2 servers , the total load a system can handle is only 200 requests per min. however, if the load increases to 1000 requests per min, ours servers become a bottleneck and response time for the clients will be affected. In the system shown above, we have multiple copes of web servers and App servers so that this kind of bottleneck is eliminated