6 step system design framework for non-technical PMs


This article explains a 6-step framework that non-technical PMs can use to crack system design interview questions
Step 1: list major functional and non-functional requirements
Functional requirements — Features/use cases that the product should support
Nonfunctional requirements — characteristics of the system. Some examples of non functional requirements are
Availability ( high availability follows no single point of failure principle)
Latency ( low latency corresponds to high performance which follows no bottleneck principle)
Consistency ( eventual vs immediate consistency)
Scalability ( caching and sharding techniques)
Fault-tolerant ( usually achieved through replication and reliability)
Step 2: API endpoints
The functional requirements outlined in Step 1 will be used as a guideline for defining API endpoints.
The general structure of an API endpoint:
< datatype the function will return> <name of API contract> ( argument1, argument2, …..)
example: to create a user, the API is long createUser( username, emailid)
Step 3: Choosing the right database
choice of DB directly impacts the non-functional requirements of a system
Use cases and appropriate databases:
For caching, redis is battle tested and is commonly used
For videos/images, blob storage such as Amazon S3 is usually used. blob storage can be used in combination with CDN ( content delivery network). CDN is used to store static files. Replicating static content across geography is achieved through CDN. This keeps the latency low irrespective of where a client request is coming from
To provide text search/fuzzy search capability on data, search engines such as Elastic search or Solr are used. However, search engines, unlike databases, do not provide any guarantee of persisting the data. Therefore search engines should be used as secondary storage while primary storage should be in a database
For building a metric-focused application, time series databases ( Open TSDB) can be used. Time series database is sort of an extension to RDBMS. In time series database, the writes are not random but sequential and reads are usually bulky
For performing analytics, the data is usually dumped in a data warehouse. Advanced querying capabilities are provided on top of this for reporting. A good example of such a data warehouse is Hadoop
Mindmap for selecting a database:

In real-world applications, usually a combination of two or more databases are used. For example, in Amazon, order inventory can be stored in RDBMS because of its requirement of ACID properties, and the same data can be moved to columnar DB once the order is delivered because of its nature of ever-increasing data and finite queries.
Step 4: the back of the envelope calculations
Start with the assumption point. For example, x write requests per sec and each write request is y kb. Calculate the following based on this assumption
# of write requests per day/year
kbs/Mbs of writes per day/ year ( derive total disk space needed from this)
Reads: writes is usually 1:5 or 1:10 depending on the use case
assume each server handles “Z’ reads per second. Therefore derive the total read servers and total write servers needed
assume 20% of writes per day is responsible for 80% of reads per day. So the cache is 0.2 * MBs of writes per day
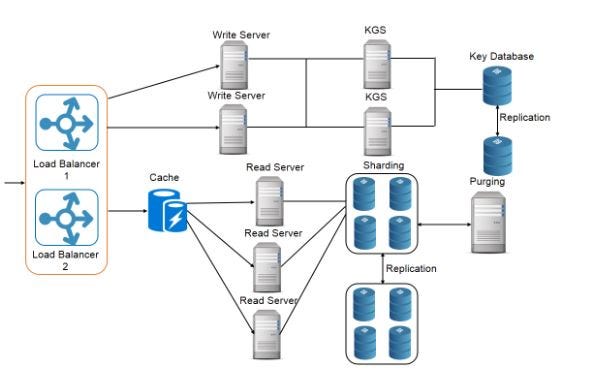
Step 5: high-level design
Draw the flow of read and write requests from client to app server to app database. You can go one level up and divide the app servers into read servers and write servers.
Example high-level design diagram:

Step 6: Scale the design
To scale the system, refer to the non-functional requirements defined in Step 1
- Replication strategies:
1. a lot of reads? — go for a simple leader-follower replication strategy
- Need to increase reliability? — go for a multi-leader replication strategy
3. a lot of writes or scale up globally? — leaderless solution
- Improve reliability:
Retry: A simple retry strategy could work for unusual and transient errors ( bugs, application errors etc). For common non-transient errors ( network failures), delayed retries could work to not overload the downstream systems once the network issues are fixed
Circuit breakers: This is useful for non-transient errors. The circuit detects the problem, cuts off the requests, and restores access once the repairs are complete.
Saga: Mostly used in microservice architecture that entails completing a set of transactions across multiple services.
- Database sharding:
- Geo-based: data is partitioned based on the user’s location
2. Range based : divides data based on range of key values
3. Hash based
Example diagram: